1.修改配置文件
1.1 修改.bashrc文件
客户端执行:
vi ~/.bashrc按
i进入编辑模式,按方向键到文件最后一行,输入export TERM=xterm-color
按
Esc键退出编辑模式,输入:wq保存退出使
.bashrc配置生效:source ~/.bashrc
1.2 下载 spark
在主节点执行:
启动HDFS服务(已经启动直接下一步):
~/hadoop-2.10.1/sbin/start-dfs.sh下载Spark安装包:
wget http://archive.apache.org/dist/spark/spark-2.4.7/spark-2.4.7-bin-without-hadoop.tgz解压安装包:
tar -zxvf spark-2.4.7-bin-without-hadoop.tgz改名:
mv ~/spark-2.4.7-bin-without-hadoop ~/spark-2.4.7
上述步骤完成后: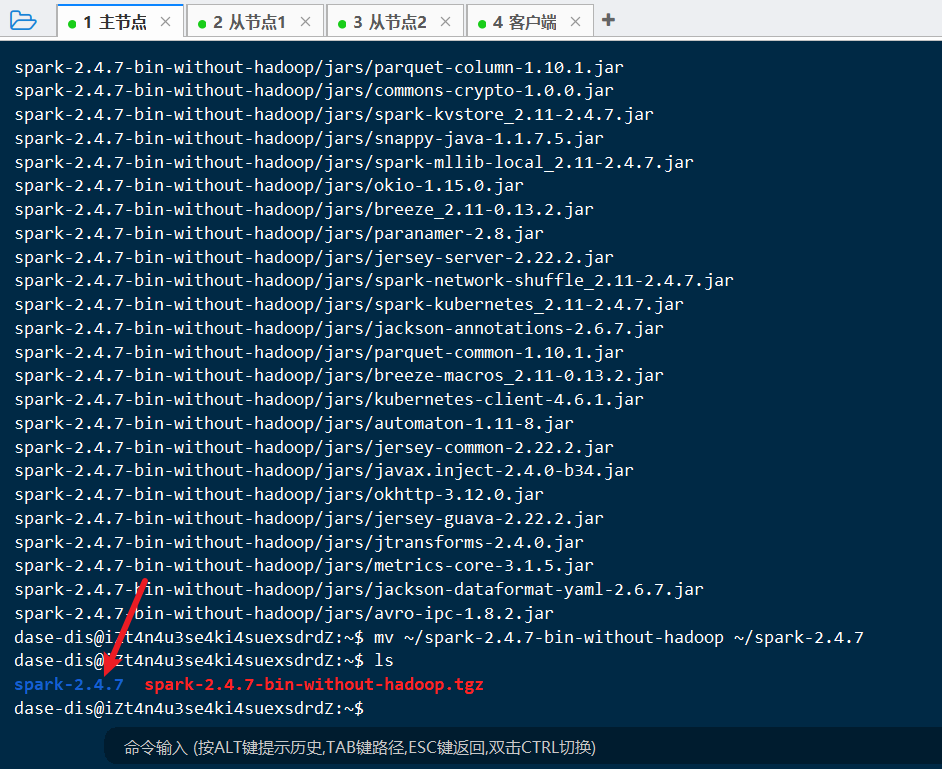
1.3 修改配置
在主节点执行以下修改:
1.3.1 spark-env
cp /home/dase-dis/spark-2.4.7/conf/spark-env.sh.template /home/dase-dis/spark-2.4.7/conf/spark-env.shvi /home/dase-dis/spark-2.4.7/conf/spark-env.sh
修改为:
1 | 因为下载的是Hadoop Free版本的Spark, 所以需要配置Hadoop的路径 |
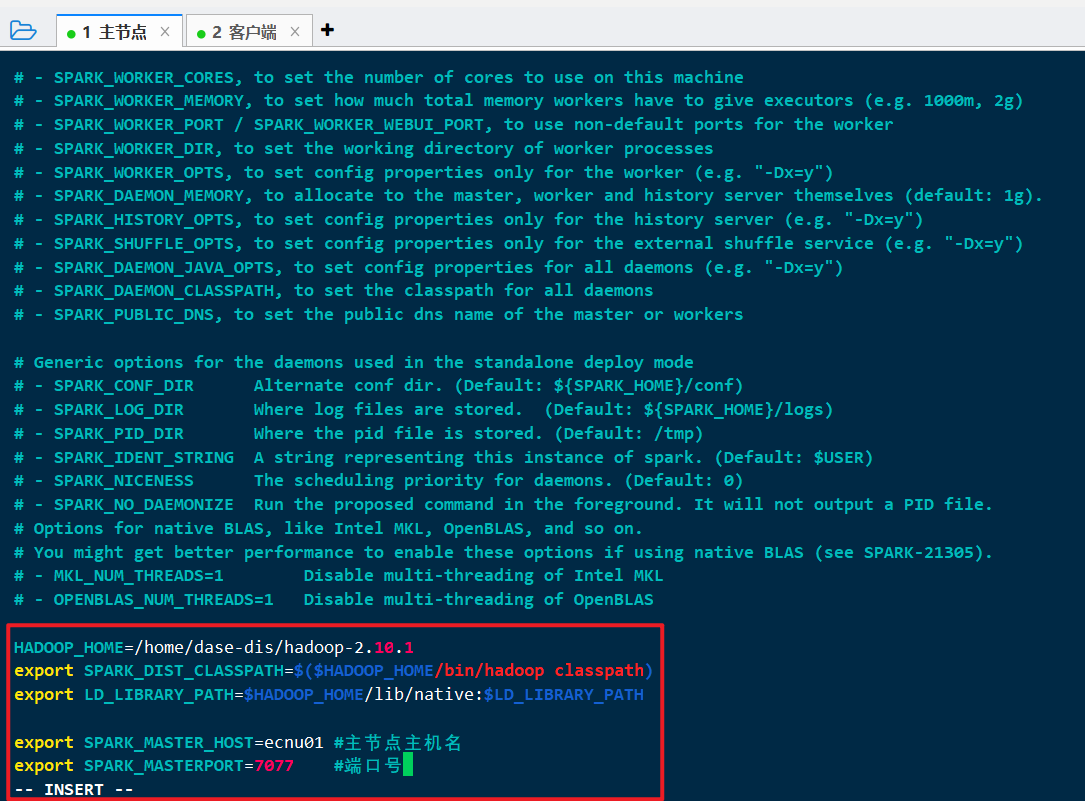
1.3.2 slaves
cp spark-2.4.7/conf/slaves.template spark-2.4.7/conf/slavesvi spark-2.4.7/conf/slaves
修改为:
1 | localhost |
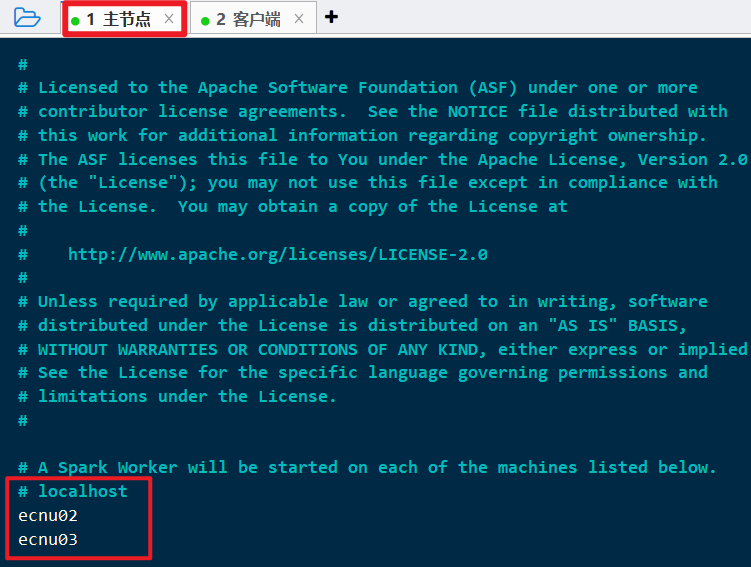
1.3.3 spark-defaults
cp spark-2.4.7/conf/spark-defaults.conf.template spark-2.4.7/conf/spark-defaults.confvi spark-2.4.7/conf/spark-defaults.conf
修改为:
1 | spark.eventLog.enabled=true |
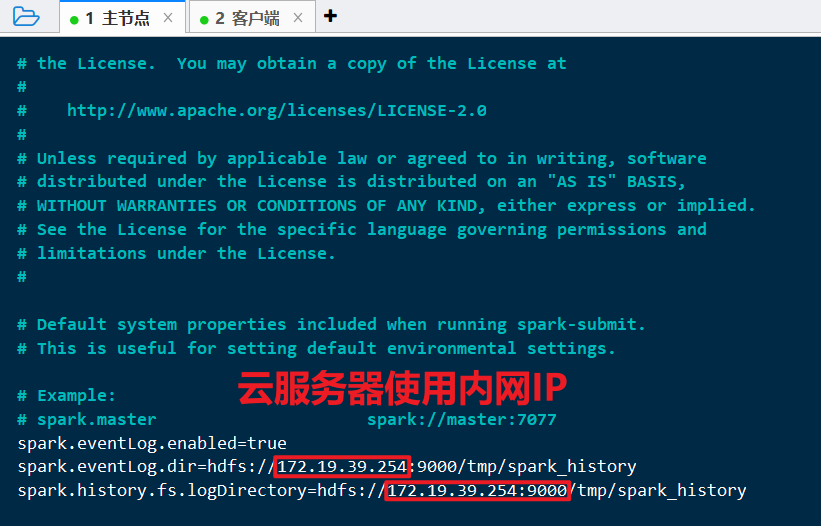
1.3.4 spark-config
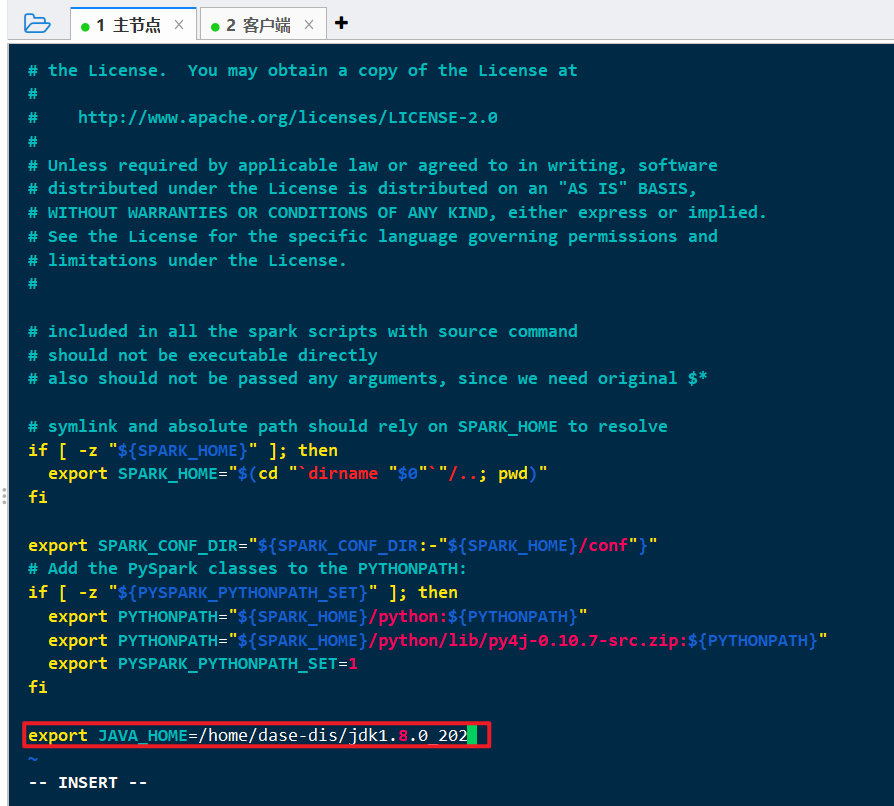
vi spark-2.4.7/sbin/spark-config.sh
追加:
1 | export JAVA_HOME=/home/dase-dis/jdk1.8.0_202 |
2.安装spark
2.1 拷贝
本步骤将spark修改好的安装包拷贝到其他三台机:
scp -r spark-2.4.7 dase-dis@ecnu02:~/scp -r spark-2.4.7 dase-dis@ecnu03:~/scp -r spark-2.4.7 dase-dis@ecnu04:~/
2.2 HDFS中建立日志目录
~/hadoop-2.10.1/bin/hdfs dfs -mkdir -p /tmp/spark_history
2.3 启动 spark
千辛万苦, 终于到启动了
在主节点执行:
启动spark:
~/spark-2.4.7/sbin/start-all.sh启动日志服务器:
~/spark-2.4.7/sbin/start-history-server.sh主节点:
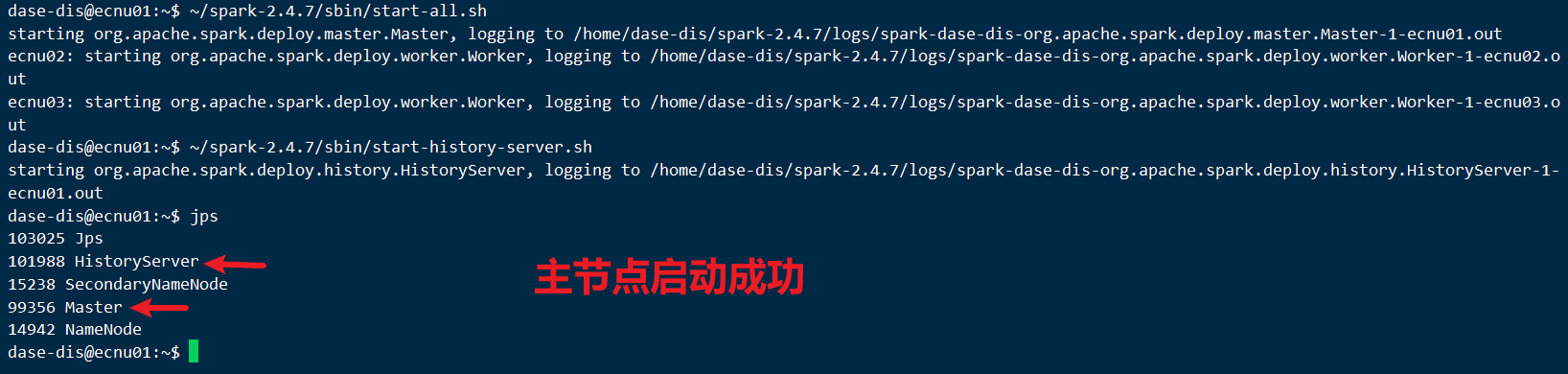
- 从节点:
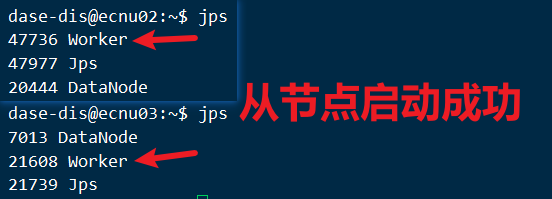
错误处理:
1 | dase-dis@ecnu01:~$ ~/spark-2.4.7/sbin/start-all.sh |
请检查hosts文件设置, 文章[大数据]Spark-1 SSH & JDK部署
2.4 验证
浏览器访问: http://主节点IP:8080/,(如果主节点是云服务器记得把防火墙打开)
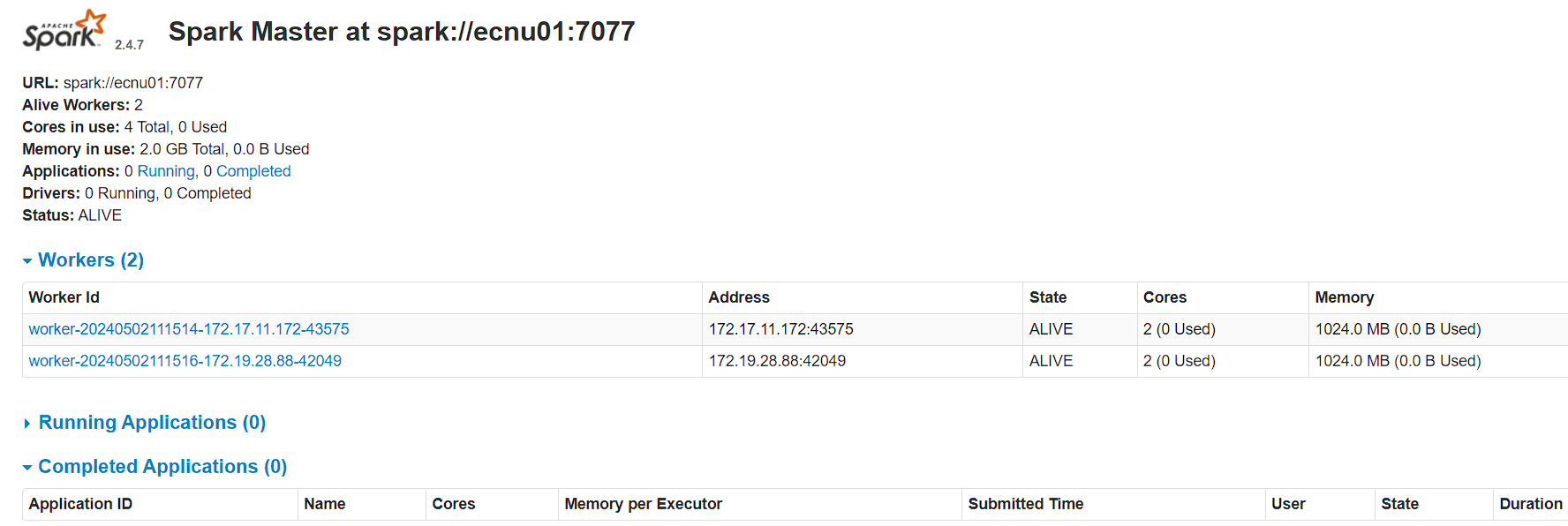
可以看到有两个worker在线, 大功告成
3.运行spark应用程序
好不容易搞好了, 来玩一下:
3.1 创建文件夹&上传文件
创建
spark_input文件夹:~/hadoop-2.10.1/bin/hdfs dfs -mkdir -p spark_input上传文件
RELEASE到spark_input:~/hadoop-2.10.1/bin/hdfs dfs -put ~/spark-2.4.7/RELEASE spark_input/
在hadood的页面可以看到, 文件RELEASE存储在两个节点中:
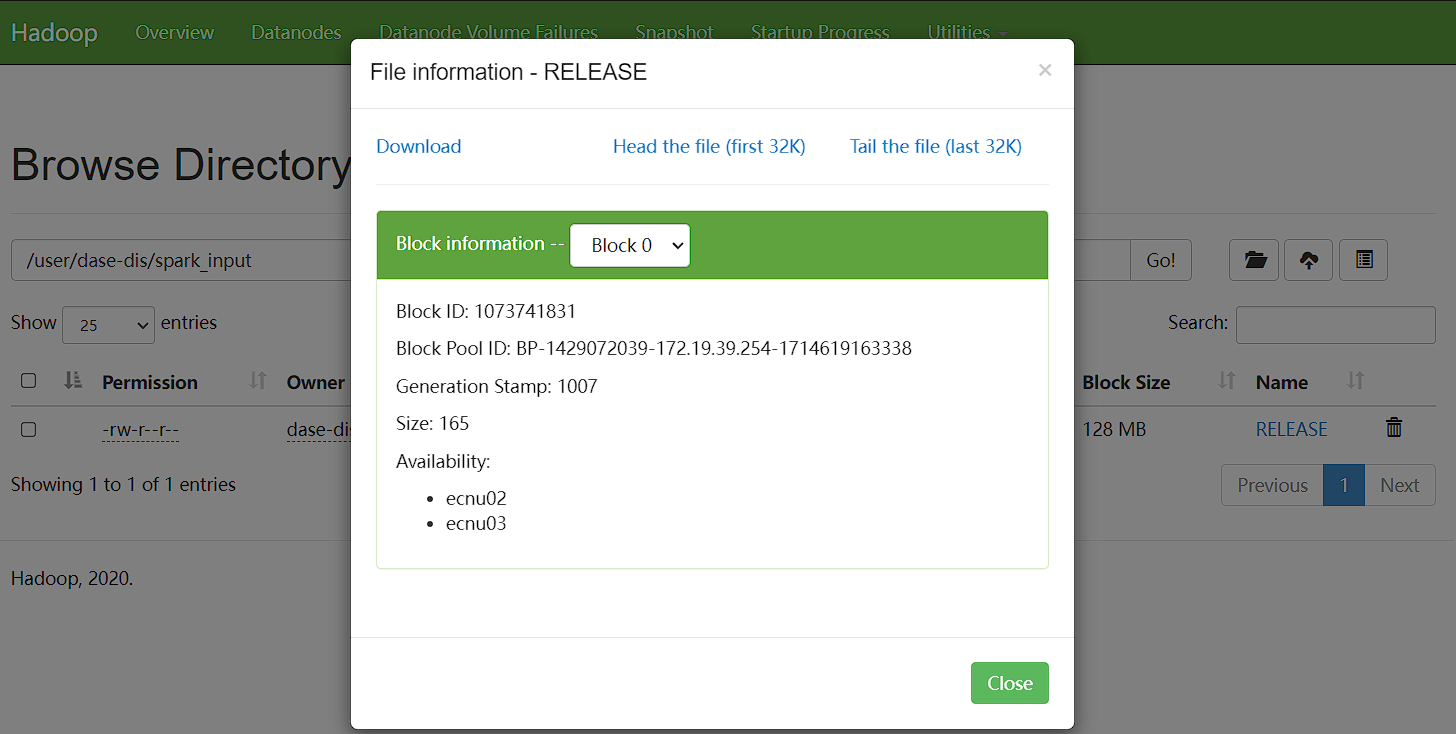
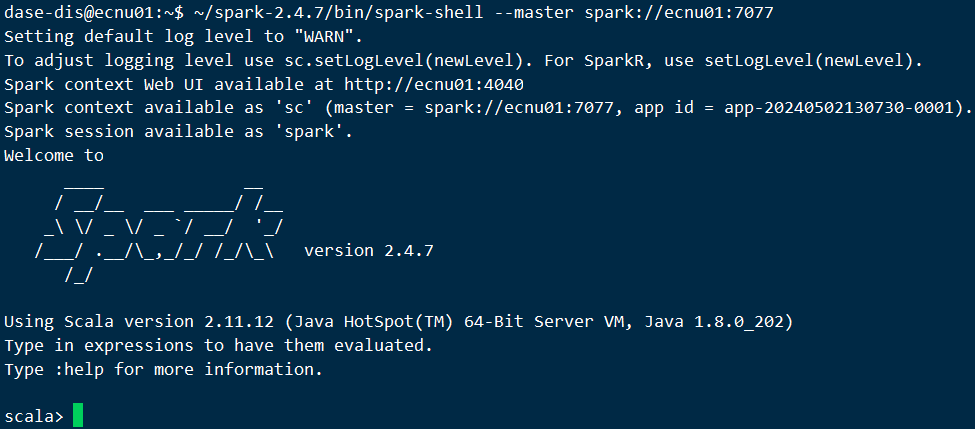
3.2 启动 Spark Shell
- 启动
spark-shell:~/spark-2.4.7/bin/spark-shell --master spark://ecnu01:7077
- 键入以下
Scala代码:
1 | val sc = spark.sparkContext |
shell输出:
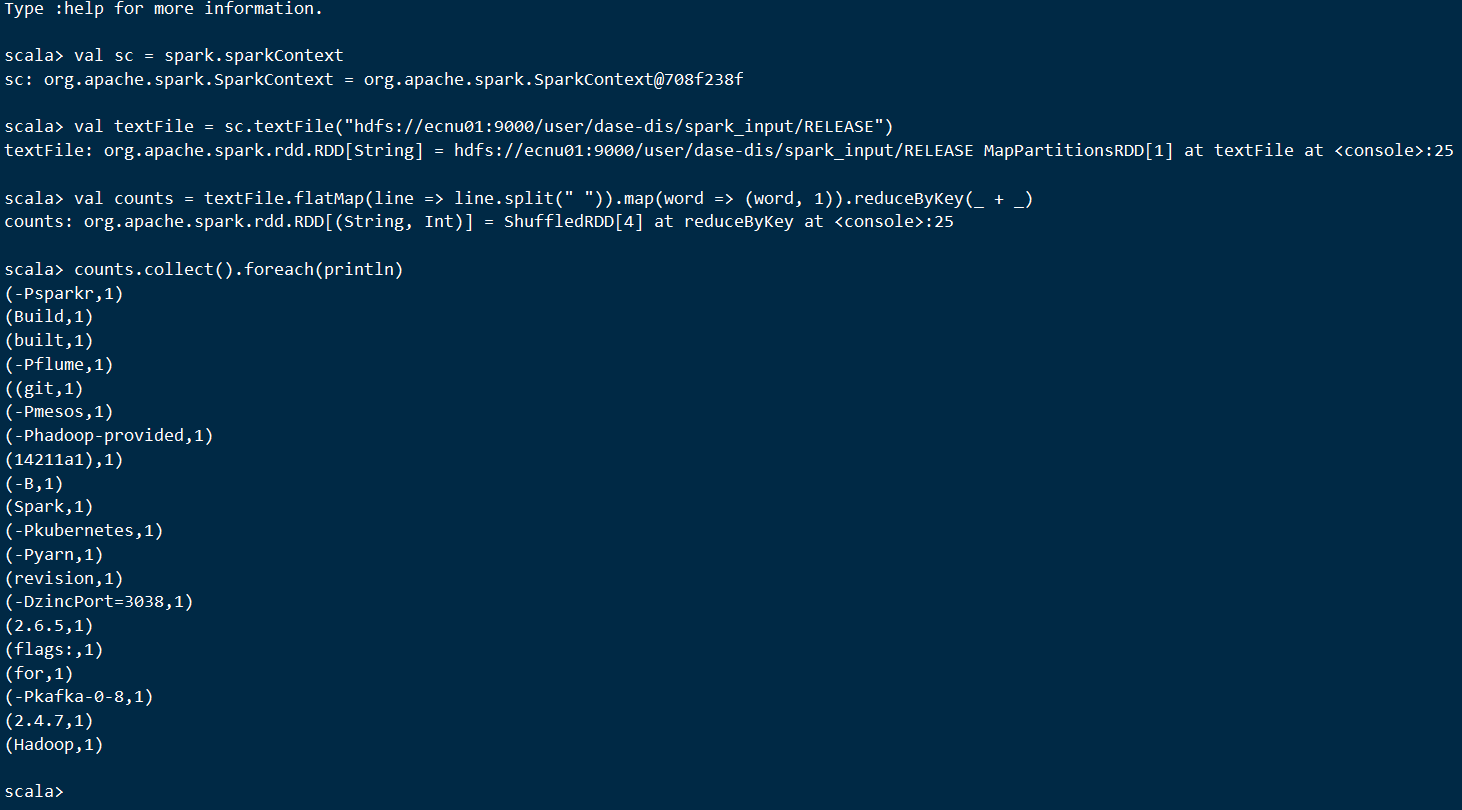
可以在网页查看到正在运行的任务信息:
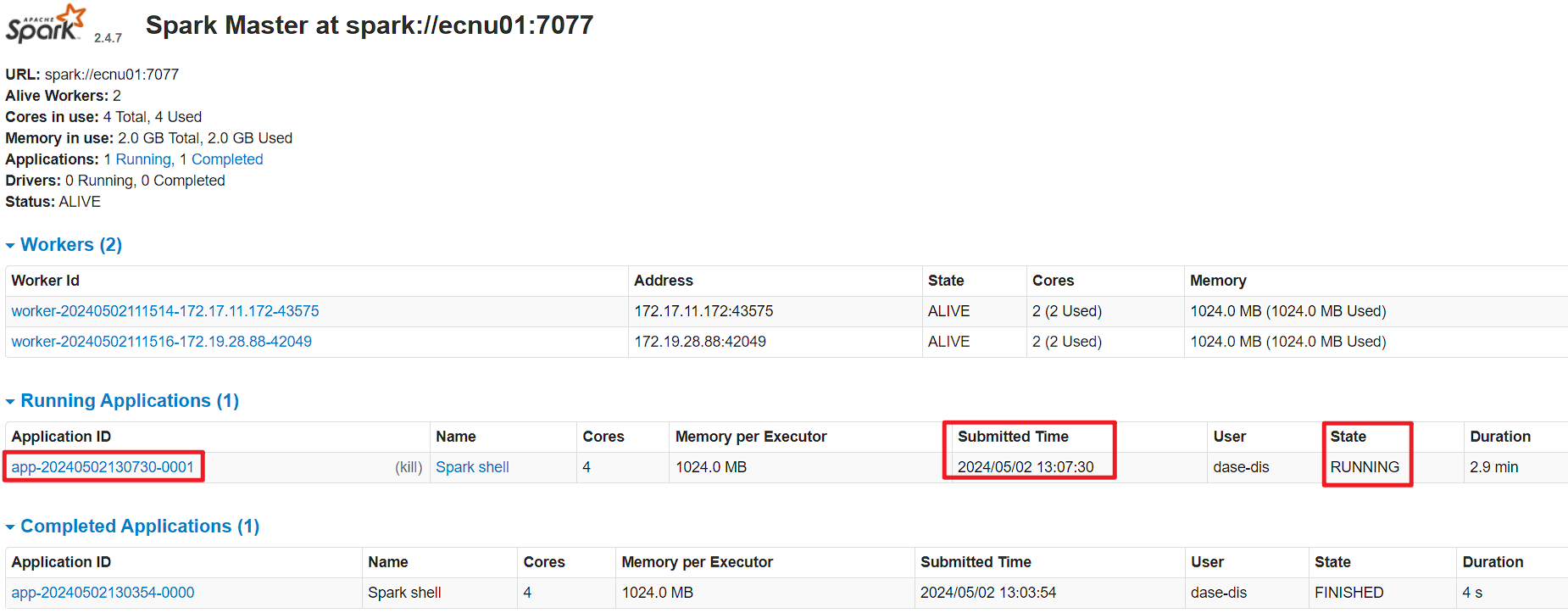
到此Spark集群就已经顺利搭建完毕了
4.停止集群
如果你希望停止集群:
停止
Spark:/spark-2.4.7/sbin/stop-all.sh停止
Spark日志服务:/spark-2.4.7/sbin/stop-history-server.sh停止
HDFS服务:/hadoop-2.10.1/sbin/stop-dfs.sh